Home > Tech Gallery > Technology Feast | Talk about the next generation 25G/100G data centre network

Time: November 11th, 2024




Traditional chassis switches have become an obstacle to the ongoing rapid evolution of data center network architecture. Can single-chip box switches take over the market?
Background
Data center networks serve as a fundamental infrastructure for the rapid and sustainable development of Internet services. These networks have significantly evolved, transitioning from Gigabit networks to 10 Gigabit networks, and now to the large-scale deployment of 25G and 100G networks. This rapid advancement in network performance has effectively addressed the increasing demand for bandwidth services. Nonetheless, despite the availability of 25G and 100G networks, discussions regarding "next-generation 25G/100G data center networks" persist. It is essential to critically evaluate whether this "next generation" is a legitimate advancement or merely a marketing strategy.
What are the challenges currently confronting data center networks?
The "uncertainty" inherent in business presents a significant challenge to the advancement of data center network technology. It is widely acknowledged that the progression of technology is driven by business development. However, from a business perspective, achieving clarity about its operations proves to be complex, revealing various forms of "uncertainty," including ambiguity related to business content, technology, and deployment. Furthermore, understanding and keeping pace with business demands from a basic network perspective poses substantial challenges to the traditionally passive evolution of data center networks.
In light of these uncertainties, it is imperative to consider the role of the network. Should the network continue to adopt a passive evolution model, ensuring timely and architecturally mature adaptations will be exceedingly difficult. Consequently, the design of network architecture must embrace a "deterministic" strategy to proactively address the uncertainties associated with business operations. This proactive approach can be articulated through several key points:
In light of these uncertainties, it is imperative to consider the role of the network. Should the network continue to adopt a passive evolution model, ensuring timely and architecturally mature adaptations will be exceedingly difficult. Consequently, the design of network architecture must embrace a "deterministic" strategy to proactively address the uncertainties associated with business operations. This proactive approach can be articulated through several key points:
1. Continuous enhancement of network performance is essential, which includes providing greater forwarding performance, boosting server access bandwidth, increasing uplink bandwidth, and minimizing network convergence delays. Additionally, achieving ultra-low latency forwarding through RDMA technology is a critical component of performance improvement.
2. Ongoing improvements in network stability are vital, especially in high-bandwidth scenarios where stability becomes paramount. The risk associated with any single point of failure can result in significant losses. Therefore, it is crucial not only to ensure the high reliability of the network itself but also to enhance operational and maintenance capabilities to establish simple, standardized, and unified networking practices.
3. It is also important to expand the scale of individual server clusters while reducing the network construction costs associated with each server. It is recommended that a single cluster be capable of supporting up to 100,000 servers. The objective here is to achieve large-scale traffic concentration, significantly lowering the cost of data center interconnection (DCI), while simultaneously enhancing performance and decreasing forwarding latency.
In conclusion, the evolution of network architecture must continually and rapidly iterate to address the various uncertainties in business operations by focusing on improvements in performance, stability, and scalability. By transitioning away from a passive stance at the network level, organizations can allocate greater resources and capabilities toward exploring and developing innovative technical solutions that are aligned with business needs. As a result, the 25G/100G data center network has emerged as the prevailing standard in the current landscape.
In conclusion, the evolution of network architecture must continually and rapidly iterate to address the various uncertainties in business operations by focusing on improvements in performance, stability, and scalability. By transitioning away from a passive stance at the network level, organizations can allocate greater resources and capabilities toward exploring and developing innovative technical solutions that are aligned with business needs. As a result, the 25G/100G data center network has emerged as the prevailing standard in the current landscape.
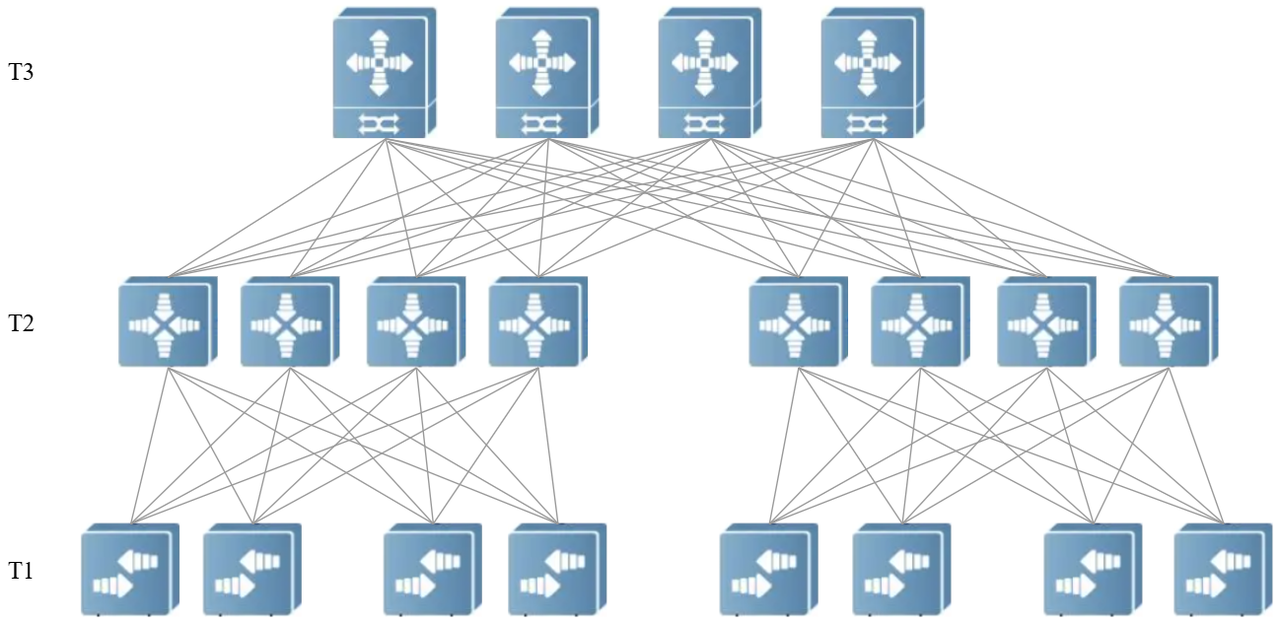
▲ Figure 1 Traditional 25G/100G data center network architecture
The traditional 25G/100G data center network, as illustrated in the preceding figure, is capable of providing 25G or 100G access to servers. Large-scale networking is facilitated through a three-tier architecture, enabling a single cluster server to support over 50,000 units. The Server-Pod configuration, which combines T1 and T2, allows for flexible horizontal expansion akin to modular building blocks, supporting on-demand construction. At first glance, this architecture may appear optimal. However, when considering the future requirement for bandwidth upgrades to 400G or 800G, the necessity for ongoing advancements within this architecture warrants examination.
The necessity for iterative upgrades in 25G and 100G data centre networks remains a pertinent topic of discussion.
The rationale for the necessary evolution of traditional 25G/100G data center networks is primarily linked to the T3 device, as illustrated in Figure 1. In conventional large-scale 10G and 25G/100G data center networks, the T3-layer device predominantly functions as a frame switch with a multi-slot architecture, specifically a chassis system. While chassis technologies have effectively supported operational needs in previous data centers and Metropolitan Area Networks (MAN), they have now become impediments to the ongoing rapid advancements in future network architectures. This evolution is driven by the demand for greater scalability, cost efficiency, and accelerated deployment.

▲ Figure 2 Chassis switch
● The multi-chip architecture of the chassis switch results in increased forwarding delay
The chassis switch employs a multi-chip architecture. The majority of the interface boards and fabric boards utilize a combination of several switch chips to achieve enhanced performance and increased port density, as illustrated in the accompanying figure.

▲ Figure 3 36*100G interface line cards
Nonetheless, this multi-chip configuration incurs an increased forwarding delay, as illustrated in Figure 4 below:

▲ Figure 4 Schematic diagram of internal forwarding in a chassis multi-chip
In the preceding diagram, two distinct data flows are illustrated. Regardless of whether the forwarding occurs across multiple boards or between two ports located on the same board, there exists a minimum of three hops within the chassis switch. The theoretical latency associated with this process is approximately 10 microseconds. While 10 microseconds may appear negligible, it is a significant factor for the service, particularly since ultra-low latency forwarding services utilizing Remote Direct Memory Access (RDMA) achieve an optimized end-to-end latency of 1 microsecond. Consequently, the latency introduced by a multi-chip architecture is a critical consideration.
● Chassis switches impede the ongoing efforts to decrease networking costs on a per-server basis
The cost of networking per server associated with traditional chassis switches differs significantly from that of single-chip box switches, particularly when the scale of a single cluster server is limited.
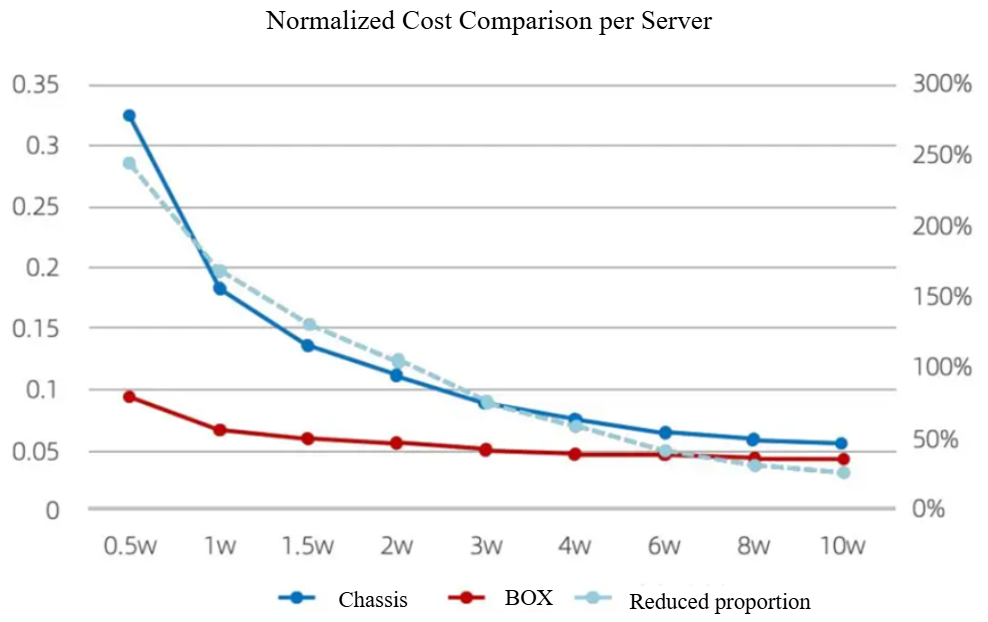
▲ Figure 5 Chassis Switches and Single-Chip Processors
Analysis of Network Cost per Server for Box Switches
(The blue solid line represents the chassis switch, and the red solid line represents the single-chip box switch.)
Figure 5 illustrates the comparative costs associated with networking per server when utilizing chassis switches (equipped with 576*100G interfaces) versus single-chip box switches (with 128*100G interfaces) across various scales of server networking. This analysis incorporates essential components such as switches and cables, and the costs have been normalized to facilitate an intuitive understanding of the distinctions.
It is evident that when the scale of a single cluster server is less than 20,000, there is a significant disparity in cost per server between the two networking configurations. Even at a scale of 100,000 servers within a single cluster, the cost per server remains over 20% different between the two approaches.
Note 1: The simulation setup compares one chassis switch with four single-chip box switches to ensure that the total number of ports remains equal. This model is based on specific assumptions, particularly that the interconnection of four single-chip box switches does not necessitate independent fabrics to function collectively.
Moreover, the indirect costs associated with chassis switch networking are substantial and pose challenges for continuous future iterations. A primary concern pertains to the high power consumption of chassis switches, which obstructs the swift deployment of essential network infrastructures, rendering them unsustainable. Due to their multi-board and multi-chip designs, chassis switches exhibit increasing power consumption as the interface rates and densities are enhanced. For instance, the typical power consumption of a chassis switch with 16 slots and 576*100G interfaces is approximately 20kW. Should it be upgraded to full 400G interfaces, the total power consumption is projected to reach 50kW, complicating the power supply line upgrades within data centers. Such transitions entail lengthy cycles, which could be infeasible, significantly hampering the business requirements for the rapid deployment of foundational networks and incurring considerable time and material costs. Additionally, the elevated power consumption of chassis switches poses thermal management challenges that necessitate specialized designs, further escalating costs.
Chassis switches also present larger physical dimensions. A 16-slot, 36-port 100G switch has a height as low as 21U, whereas a 16-slot, 36-port 400G switch exceeds 30U in height, necessitating more cabinet space, which further contributes to overall expenses.
It is evident that when the scale of a single cluster server is less than 20,000, there is a significant disparity in cost per server between the two networking configurations. Even at a scale of 100,000 servers within a single cluster, the cost per server remains over 20% different between the two approaches.
Note 1: The simulation setup compares one chassis switch with four single-chip box switches to ensure that the total number of ports remains equal. This model is based on specific assumptions, particularly that the interconnection of four single-chip box switches does not necessitate independent fabrics to function collectively.
Moreover, the indirect costs associated with chassis switch networking are substantial and pose challenges for continuous future iterations. A primary concern pertains to the high power consumption of chassis switches, which obstructs the swift deployment of essential network infrastructures, rendering them unsustainable. Due to their multi-board and multi-chip designs, chassis switches exhibit increasing power consumption as the interface rates and densities are enhanced. For instance, the typical power consumption of a chassis switch with 16 slots and 576*100G interfaces is approximately 20kW. Should it be upgraded to full 400G interfaces, the total power consumption is projected to reach 50kW, complicating the power supply line upgrades within data centers. Such transitions entail lengthy cycles, which could be infeasible, significantly hampering the business requirements for the rapid deployment of foundational networks and incurring considerable time and material costs. Additionally, the elevated power consumption of chassis switches poses thermal management challenges that necessitate specialized designs, further escalating costs.
Chassis switches also present larger physical dimensions. A 16-slot, 36-port 100G switch has a height as low as 21U, whereas a 16-slot, 36-port 400G switch exceeds 30U in height, necessitating more cabinet space, which further contributes to overall expenses.
Furthermore, due to the intricacies associated with chassis chips and their structural complexity, network architects and operational personnel must engage in more comprehensive considerations. This complexity may also require specialized adaptations within automated operation and maintenance platforms, resulting in heightened costs related to technical training and maintenance operations, which contradicts the design objective of achieving a simple, stable, and reliable network.
● Chassis switches impede the swift evolution of network architecture
Chassis switches present a notable challenge in product development and design due to their inherent complexity. As a result, the rate of updates and iterations for chassis switches is comparatively slower than that of box switches, which poses a significant drawback to the evolution of the overall network architecture.
The development of chassis switch chips and box switch chips occurs asynchronously, primarily due to variations in their technological systems. Chassis switches typically utilize dedicated chips that offer features such as large-capacity caching and cell slicing, which enable superior Quality of Service (QoS) capabilities. In contrast, the chip architecture and technology employed in chassis switches are more intricate, resulting in prolonged iteration cycles for their forwarding performance and functional characteristics. Box switch chip technology, on the other hand, is structured more simply, allowing for quicker iterations in forwarding performance and functional features, even though such chips do not typically include extensive caching. Consequently, new generations of box switch chips may be introduced approximately every 1 to 1.5 years.
When integrating both chassis switches and box switches within a network, a potential mismatch in performance and feature sets can occur. This disparity can hinder the uniform deployment of new functionalities, such as In-band Network Telemetry (INT), across the network, thereby leading to resource inefficiencies.
Furthermore, the differing chip architectures and structural configurations of chassis and box switches contribute to unsynchronized product development cycles. Chassis switches are generally constructed from multiple essential components, including a main control board, interface board, and switchboard. Each chassis comprises several boards, each containing multiple chips, necessitating a reliance on centralized computing alongside distributed processing. Additionally, synchronization across boards and chips is crucial. Consequently, the complexity and commercial development cycles associated with chassis products are significantly greater—by several orders of magnitude—than those of single-chip box switches. This complexity ultimately results in extended product development timelines, which can severely impact the iteration speed of the entire networking architecture.
The development of chassis switch chips and box switch chips occurs asynchronously, primarily due to variations in their technological systems. Chassis switches typically utilize dedicated chips that offer features such as large-capacity caching and cell slicing, which enable superior Quality of Service (QoS) capabilities. In contrast, the chip architecture and technology employed in chassis switches are more intricate, resulting in prolonged iteration cycles for their forwarding performance and functional characteristics. Box switch chip technology, on the other hand, is structured more simply, allowing for quicker iterations in forwarding performance and functional features, even though such chips do not typically include extensive caching. Consequently, new generations of box switch chips may be introduced approximately every 1 to 1.5 years.
When integrating both chassis switches and box switches within a network, a potential mismatch in performance and feature sets can occur. This disparity can hinder the uniform deployment of new functionalities, such as In-band Network Telemetry (INT), across the network, thereby leading to resource inefficiencies.
Furthermore, the differing chip architectures and structural configurations of chassis and box switches contribute to unsynchronized product development cycles. Chassis switches are generally constructed from multiple essential components, including a main control board, interface board, and switchboard. Each chassis comprises several boards, each containing multiple chips, necessitating a reliance on centralized computing alongside distributed processing. Additionally, synchronization across boards and chips is crucial. Consequently, the complexity and commercial development cycles associated with chassis products are significantly greater—by several orders of magnitude—than those of single-chip box switches. This complexity ultimately results in extended product development timelines, which can severely impact the iteration speed of the entire networking architecture.

▲ Figure 6 Complex hardware structure of chassis switch
Summary
A comparative analysis of Chassis switches and single-chip Box switches reveals that Chassis switches have emerged as a significant bottleneck in the rapid evolution of data center networks (DCNs), particularly regarding forwarding performance, construction costs, operational and maintenance expenses, and product iteration. To facilitate the swift and efficient advancement of data center networks in the future, it is imperative to address the challenges associated with Chassis switches. The adoption of single-chip Box switches in networking is anticipated to become the prevailing approach, with DE-framing likely to dominate in the coming years.
What is the appearance of the device commonly referred to as a single-chip Box?
We have dedicated significant effort to elucidating that Chassis switches have become an impediment to the ongoing evolution of future architectures. Consequently, there is a pressing need to transition to single-chip Box switches in order to facilitate DE-framing. This raises the question: what characteristics define the single-chip Box switch that could serve as a replacement for the Chassis switch?
In the current traditional Data Center Network (DCN) architecture, depicted in Figure 1, the Chassis switch operates at the T3 level. It typically comprises 16 slots and is equipped with 36-port 100G boards, resulting in a total capacity of 576*100G interfaces, as illustrated in the accompanying figure.
In the current traditional Data Center Network (DCN) architecture, depicted in Figure 1, the Chassis switch operates at the T3 level. It typically comprises 16 slots and is equipped with 36-port 100G boards, resulting in a total capacity of 576*100G interfaces, as illustrated in the accompanying figure.

▲ Figure 7 Ruijie Networks Chassis Core Switch RG-N18018-X
Box switches that are appropriate for substituting traditional chassis switches must possess the highest possible forwarding performance and a greater density of 100G interfaces. In light of the current state of the switch chip industry, the peak commercial single-chip forwarding capability is 12.8 Tbps, allowing a complete unit to support up to 128*100G interfaces. A conventional 16-slot chassis is equivalent to four single-chip box switches, as detailed below:

▲ Figure 8 Ruijie Network Single Chip
High-Density 100G Switch RG-S6920-4C
The Ruijie Networks RG-S6920-4C demonstrates advanced capabilities through its use of a high-performance switching chip, which facilitates a unidirectional forwarding performance of 12.8 Tbps. It is equipped with four pluggable sub-cards, each offering 32*100G interfaces. Anticipating the broader adoption of 400G optical modules, these sub-cards can be replaced with versions containing eight 400G interfaces, thereby enabling the entire system to support a total of 32*400G interfaces.
Based on a single-chip box switch and a multi-plane group, this technology supports next-generation hyper-scale data center networks.
What does the next-generation 25G/100G network architecture based on a single-chip Box switch look like? As shown below:

▲ Figure 9 Next-generation 25G/100G hyper-scale data center network architecture
In general, a cost-effective network architecture that facilitates continuous and seamless scale expansion in the future is characterized as an orthogonal multi-plane architecture.
Note 2: It is important to note that this is merely a proposed networking model and concept. For specific projects, it is essential to adjust the number of relevant planes and devices in accordance with the planned convergence ratio.
The overall cluster is structured based on a three-tier composition of Leaf, Pod-Spine, and Spine. In this configuration, the Leaf and Pod-Spine components form the Server-Pod. Each Server-Pod accommodates a standardized number of server units, allowing for smooth and scalable expansion by horizontally adding Server-Pods, similar to stacking blocks. Interconnectivity between multiple Server-Pods is achieved through multi-plane Spine devices that are orthogonal to the upper tier. Furthermore, high-performance single-chip Box devices are utilized at both the Server-Pod and Spine levels. Specifically, each unit is equipped with 128*100G interfaces, and the switching equipment across the entire network is limited to two specifications. This greatly simplifies the networking process as well as operations and maintenance.
Note 2: It is important to note that this is merely a proposed networking model and concept. For specific projects, it is essential to adjust the number of relevant planes and devices in accordance with the planned convergence ratio.
The overall cluster is structured based on a three-tier composition of Leaf, Pod-Spine, and Spine. In this configuration, the Leaf and Pod-Spine components form the Server-Pod. Each Server-Pod accommodates a standardized number of server units, allowing for smooth and scalable expansion by horizontally adding Server-Pods, similar to stacking blocks. Interconnectivity between multiple Server-Pods is achieved through multi-plane Spine devices that are orthogonal to the upper tier. Furthermore, high-performance single-chip Box devices are utilized at both the Server-Pod and Spine levels. Specifically, each unit is equipped with 128*100G interfaces, and the switching equipment across the entire network is limited to two specifications. This greatly simplifies the networking process as well as operations and maintenance.
● Standardized and Horizontally Scalable Server Pod
Sever-Pod architecture comprises the Leaf and Pod-Spine components. In a 25G network configuration, the typical port configuration for Leaf layer products is 48*25G plus 8*100G, resulting in a convergence ratio of 1.5:1. The Leaf devices are connected to the eight Pod-Spines within each Server-Pod via eight 100G interfaces.
The capacity for server connections within each Server-Pod is influenced by the convergence ratio as determined by the design of the Pod-Spine devices, assuming a fixed number of ports on these devices. Traditional network designs at the Pod-Spine layer typically employ a convergence ratio of 3:1. However, evolving service demands necessitate a lower convergence ratio to accommodate the substantial east-west traffic generated by the segregation of computing and storage resources, as well as the co-location of online and offline services. Given that the convergence ratio for Leaf switches is generally 1.5:1, it is advisable for the Pod-Spine to also maintain a minimum convergence ratio of 1.5:1.
Calculations indicate that a 128-port 100G single-chip Pod-Spine device utilizing 80 of its 100G ports for downstream connections and 48 for upstream connections yields a final convergence ratio of approximately 1.67:1. Nonetheless, in light of initial construction costs and the anticipated growth in network traffic, a more prudent approach may involve starting with a 2.5:1 convergence ratio. This configuration would allocate 80*100G ports for downstream and 32*100G ports for upstream, thereby minimizing the number of devices required at the Spine level. The remaining idle ports on the Pod-Spine device would accommodate future expansions and further decrease the convergence ratio.
Under this proposed configuration, if each server utilizes dual 25G uplink links, a single Server-Pod can support 48x(80/2) = 1,920 servers. Conversely, should each server rely on a singular 25G uplink link, a single Server-Pod can support 48x80 = 3,840 servers.
For such a convergence ratio design, should a single cluster require support for 100,000 servers, it would necessitate the horizontal expansion of 52 Server-Pods. Should there be a need for further expansion to accommodate a larger server scale, it would entail allocating more downstream ports on the 128-port single-chip switch devices at the Spine level to facilitate additional Pod-Spines. Ultimately, the maximum number of Server-Pods that can be supported is contingent upon the convergence ratio design implemented at the Spine level.
The capacity for server connections within each Server-Pod is influenced by the convergence ratio as determined by the design of the Pod-Spine devices, assuming a fixed number of ports on these devices. Traditional network designs at the Pod-Spine layer typically employ a convergence ratio of 3:1. However, evolving service demands necessitate a lower convergence ratio to accommodate the substantial east-west traffic generated by the segregation of computing and storage resources, as well as the co-location of online and offline services. Given that the convergence ratio for Leaf switches is generally 1.5:1, it is advisable for the Pod-Spine to also maintain a minimum convergence ratio of 1.5:1.
Calculations indicate that a 128-port 100G single-chip Pod-Spine device utilizing 80 of its 100G ports for downstream connections and 48 for upstream connections yields a final convergence ratio of approximately 1.67:1. Nonetheless, in light of initial construction costs and the anticipated growth in network traffic, a more prudent approach may involve starting with a 2.5:1 convergence ratio. This configuration would allocate 80*100G ports for downstream and 32*100G ports for upstream, thereby minimizing the number of devices required at the Spine level. The remaining idle ports on the Pod-Spine device would accommodate future expansions and further decrease the convergence ratio.
Under this proposed configuration, if each server utilizes dual 25G uplink links, a single Server-Pod can support 48x(80/2) = 1,920 servers. Conversely, should each server rely on a singular 25G uplink link, a single Server-Pod can support 48x80 = 3,840 servers.
For such a convergence ratio design, should a single cluster require support for 100,000 servers, it would necessitate the horizontal expansion of 52 Server-Pods. Should there be a need for further expansion to accommodate a larger server scale, it would entail allocating more downstream ports on the 128-port single-chip switch devices at the Spine level to facilitate additional Pod-Spines. Ultimately, the maximum number of Server-Pods that can be supported is contingent upon the convergence ratio design implemented at the Spine level.
● Unified and Cost-Effective Multi-plane Spine
At this interval, it is noteworthy that the Spine layer employs multi-slot chassis devices in traditional Data Center Network (DCN) designs. However, in the forthcoming generation of 25G and 100G architecture, these will be supplanted by single-chip 128-port 100G Box switches to facilitate DE-framing. Consequently, when formulating the convergence ratio design for the Spine layer, equipment planning will be predicated on the utilization of 128-port 100G devices.
The Spine layer will also adopt a parallel multi-plane design, featuring a plane-orthogonal connection with the Server-Pod. This design aims to maximize redundancy among all Pod-Spine connections. The overall number of hops will utilize Equal-Cost Multi-Path (ECMP) routing, which ensures optimal path forwarding while simplifying network planning.
Regarding the number of Spine layer planes, as illustrated in Figure 9, the total number of Spine planes correlates with the quantity of Pod-Spine devices within each Server-Pod. Based on current Server-Pod strategy, the entire network is required to accommodate 8 Spine planes, with each Pod-Spine upstream corresponding to an individual Spine plane.
The number of devices allocated to each Spine plane is contingent upon the convergence ratio design for the Pod-Spine. Prior recommendations for convergence ratio design stipulate that each Spine plane should incorporate 32 Spine devices, culminating in a requirement for a total of 256 Spine devices across the 8 Spine planes.
It has been established that the expansion capabilities of the Server-Pod are intrinsically linked to the convergence ratio design of the Spine device. Drawing from industry experience and considering east-west traffic dynamics between clusters, specifically Data Center Interconnect (DCI) traffic, the Spine layer in a single cluster should be designed to support a minimum convergence ratio performance of 3:1. Given a scale of 100,000 servers within a single cluster, the infrastructure will encompass 52 Server-Pods. For each Spine device, it is imperative to allocate at least 52*100G interfaces in the downstream direction and 16*100G ports in the upstream direction to establish connectivity with the Metropolitan Area Network (MAN) device, thus facilitating a convergence ratio of 3:1. In the future, the allocation of upstream and downstream 100G ports may be adjusted flexibly to correspond with changes in Server-Pod scale and convergence ratio requirements. Overall, the provision of 128 ports in the Spine is deemed highly adequate.
The Spine layer will also adopt a parallel multi-plane design, featuring a plane-orthogonal connection with the Server-Pod. This design aims to maximize redundancy among all Pod-Spine connections. The overall number of hops will utilize Equal-Cost Multi-Path (ECMP) routing, which ensures optimal path forwarding while simplifying network planning.
Regarding the number of Spine layer planes, as illustrated in Figure 9, the total number of Spine planes correlates with the quantity of Pod-Spine devices within each Server-Pod. Based on current Server-Pod strategy, the entire network is required to accommodate 8 Spine planes, with each Pod-Spine upstream corresponding to an individual Spine plane.
The number of devices allocated to each Spine plane is contingent upon the convergence ratio design for the Pod-Spine. Prior recommendations for convergence ratio design stipulate that each Spine plane should incorporate 32 Spine devices, culminating in a requirement for a total of 256 Spine devices across the 8 Spine planes.
It has been established that the expansion capabilities of the Server-Pod are intrinsically linked to the convergence ratio design of the Spine device. Drawing from industry experience and considering east-west traffic dynamics between clusters, specifically Data Center Interconnect (DCI) traffic, the Spine layer in a single cluster should be designed to support a minimum convergence ratio performance of 3:1. Given a scale of 100,000 servers within a single cluster, the infrastructure will encompass 52 Server-Pods. For each Spine device, it is imperative to allocate at least 52*100G interfaces in the downstream direction and 16*100G ports in the upstream direction to establish connectivity with the Metropolitan Area Network (MAN) device, thus facilitating a convergence ratio of 3:1. In the future, the allocation of upstream and downstream 100G ports may be adjusted flexibly to correspond with changes in Server-Pod scale and convergence ratio requirements. Overall, the provision of 128 ports in the Spine is deemed highly adequate.
A complete data centre is more than just Leaf and Spine.
The previously detailed content primarily addresses the most critical components of a data center network (DCN), specifically the Leaf, Leaf-Spine, and Spine elements. However, these three components alone do not provide a comprehensive view of the architecture. It is essential to consider how to facilitate inter-cluster connectivity and external service provision. Consequently, for a complete data center environment, it is pertinent to examine the overall architectural framework.
For the entirety of the data center park, we recommend an architecture that is predicated on the distinction between the intranets and extranet, aimed at establishing an ultra-large-scale data center park.
For the entirety of the data center park, we recommend an architecture that is predicated on the distinction between the intranets and extranet, aimed at establishing an ultra-large-scale data center park.
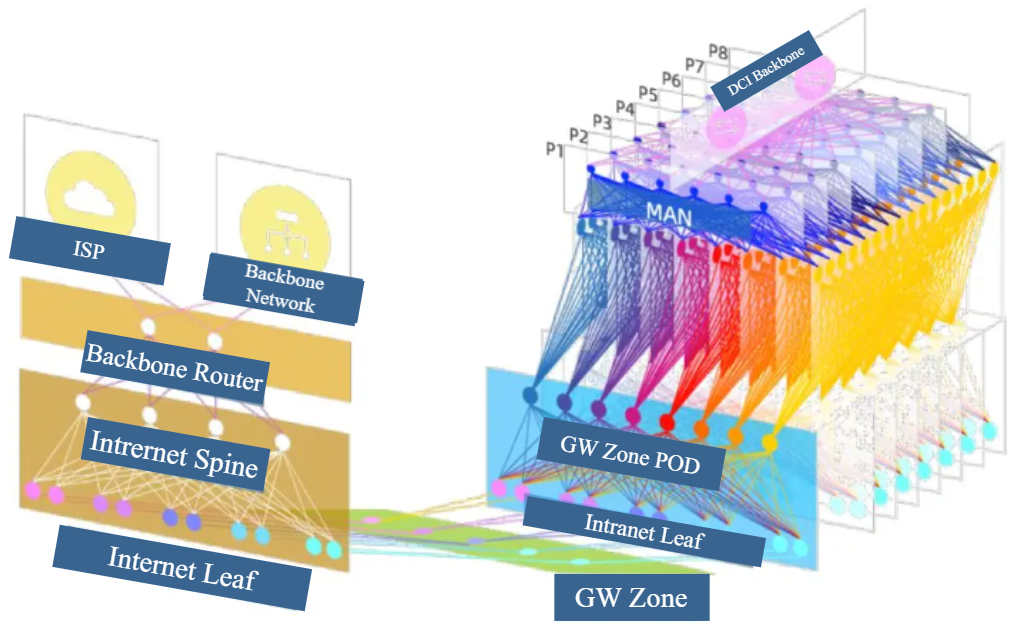
▲ Figure 10 Ultra-Large-Scale Campus Architecture Based on Single-Chip Box Switch Networking
● First, there is a necessity to segregate the internal and external networks. The external network serves as the connection to the operator and facilitates end users in accessing data center services. Conversely, the internal network primarily manages east-west traffic among servers within the data center. The rationale for implementing a networking strategy that separates the internal and external networks is to minimize cost increases, clarify the network boundaries, simplify data planning and management of network equipment, and enable independent operation and maintenance.
● The Gateway (GW) infrastructure is established based on the park, incorporating elements such as Load Balancing, Network Address Translation (NAT), and dedicated access gateways. This design acknowledges that the configuration and performance requirements for GW-related services differ significantly from those associated with standard operations, as do their network performance needs. Independent construction supports optimized planning, operation and maintenance, and overall performance benefits.
● Moreover, the Metropolitan Area Network (MAN) architecture at the park level is designed to achieve high-speed east-west interconnectivity between clusters within the same park and to establish connections to other parks via the MAN. Regarding the network equipment utilized in the MAN plane, if it is determined that there is no pressing requirement for switches with large-capacity caching capabilities, consideration may be given to eliminating the frame and deploying a single-chip 128-port 100G Box switch. This approach may reduce construction and operational maintenance costs. It is assumed that six units will be deployed on each plane, leading to the establishment of a total of eight planes.
Previous representations of the park structure were rendered as a three-dimensional schematic. To enhance comprehension, a two-dimensional plan is now provided for clarity.
Previous representations of the park structure were rendered as a three-dimensional schematic. To enhance comprehension, a two-dimensional plan is now provided for clarity.
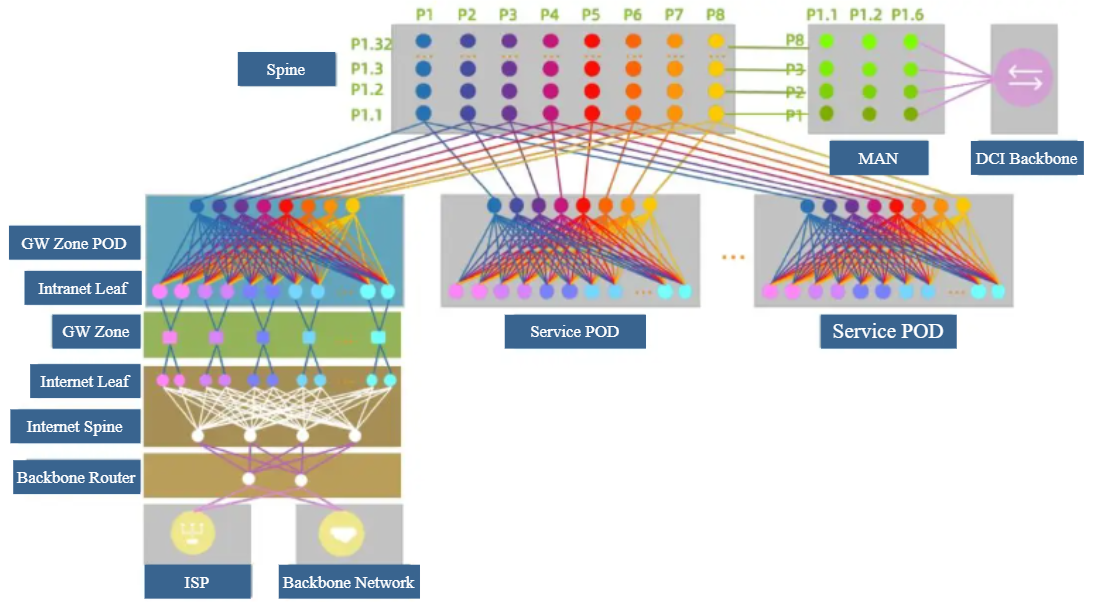
▲ Figure 11 Ultra-large-scale campus architecture based on single-chip Box switch networking (two-dimensional diagram).
Summary: Benefits of networking based on a single-chip Box switch
The deployment of a single-chip Box switch in conjunction with multi-plane networking facilitates the implementation of ultra-large-scale next-generation 25G/100G data center networking. The core concept involves the establishment of DE-framing utilizing a single-chip Box switch within the Data Center Network (DCN). This approach is designed to accommodate the continuous evolution of future networks while offering substantial advantages in network scalability, cost-efficiency, and overall performance. The specific benefits are delineated as follows:
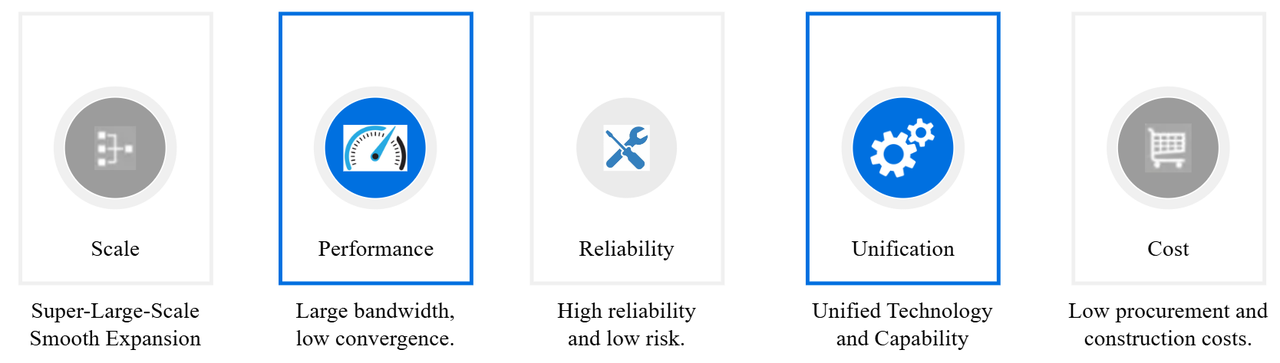
▲ Figure 12 Summary of Benefits for Single Chip Box Switches
1. Super Large Scale
A single server pod is capable of supporting 2,000 servers, while a single cluster can accommodate up to 100,000 servers. This architecture allows for flexible expansion on demand, following the Server-Pod approach.
2. High Performance
2. High Performance
Each server offers an uplink bandwidth of 50 Gbps, facilitating 25 Gbps server access. Each server group provides an upstream bandwidth of 1.6 Tbps, and each Server-Pod can deliver a total upstream bandwidth of 25.6 Tbps. This system is designed to achieve a lower convergence ratio, providing a unified RDMA service bearer from end to end, ensuring high-performance throughput and ultra-low latency forwarding for services.
3.High-Reliability
3.High-Reliability
The entire network is structured using CLOS networking, eliminating any single point of failure. The design allows for chassis removal, thereby minimizing the impact of specific points of failure on business operations. The Leaf "DE-stacking" design is implemented to ensure reliable server access while simplifying the management and maintenance of Leaf components.
4. Technical Unification
4. Technical Unification
The system employs unified chip technology, leveraging consistent technological advantages to provide comprehensive capability support for business needs. By utilizing a unified architectural framework, the system simplifies operations and maintenance, facilitates the integration of operational capabilities and experiences, and reduces overall costs.
5. Low-Cost
The implementation significantly lowers hardware expenses. When compared to chassis switches with equivalent port density, the hardware cost of single-chip box switches is reduced by 47%. Additionally, power costs are notably decreased; single-chip box switches consume 71% less power than chassis switches of the same port density. The elimination of the need for separate power transformation further diminishes heat dissipation requirements, thereby accelerating project delivery cycles. Lastly, the use of single-chip box switches can lead to a 24% reduction in space costs relative to chassis switches with the same port density.
What are there other benefits of single-chip Box networking?
Through the comprehensive analysis presented above, replacing the traditional chassis within the data center network (DCN) with a single-chip Box switch can yield significant advantages in terms of scalability, cost-effectiveness, and reliability. Nevertheless, this consideration predominantly pertains to the foundational layer. More impactful for the business sector are the capabilities related to architecture and the operational maintenance assurances that arise from the unification of the chip. These aspects are outlined as follows:

▲ Figure 13 Open and Unified Map of Next-Generation Internet Data Center Capabilities
As illustrated in the preceding figure, the development of a highly cost-effective ultra-large-scale data centre network entails not only foundational infrastructure but also robust business-oriented capabilities. These capabilities encompass the end-to-end deployment of RDMA services as well as the provision of dual-stack support for both IPv4 and IPv6 within the data centre environment. Furthermore, leveraging advancements in next-generation switch chip technology architecture, there are comprehensive and standardized operations and maintenance capabilities available. These include visual operation and maintenance, unified operation and maintenance, open operation and maintenance, as well as intelligent operation and maintenance.
Given the constraints of this article, a detailed exploration of these technical aspects will not be undertaken at this time. We encourage readers to remain attentive to forthcoming publications that will delve deeper into these topics.
Given the constraints of this article, a detailed exploration of these technical aspects will not be undertaken at this time. We encourage readers to remain attentive to forthcoming publications that will delve deeper into these topics.
Summary
This article has extensively examined the emerging landscape of 25G/100G hyper-scale data centers. A central theme is that traditional chassis switches are increasingly seen as impediments to the ongoing rapid evolution of data center network (DCN) architecture. In terms of performance, cost efficiency, and upgrade capabilities, chassis switches are progressively outmatched by high-performance, high-density single-chip box switches. However, this does not imply that chassis switches have become obsolete or that single-chip box switches will dominate the market entirely. Chassis switches possess technical advantages, including substantial cache capacities that single-chip box switches cannot replicate. Furthermore, with technologies such as cell slicing and virtual output queuing (VoQ), chassis switches offer robust Quality of Service (QoS) management capabilities, effectively mitigating packet loss during business surges under bandwidth constraints.
Current assessments from major Internet companies indicate that within cluster environments, single-chip box switches are preferable to traditional chassis switches. In contrast, for the construction of metropolitan area networks (MAN) and data center interconnect (DCI) backbone infrastructures, a greater reliance on chassis switches is evident, particularly due to their large cache capacities and high port density on individual machines.
It is reasonable to anticipate that future enterprises will place increased demands on the performance, scalability, reliability, and cost of data center networks. As the capabilities of single-chip box switches continue to advance, systems with single-chip performance levels of 25.6 Tbps and 51.2 Tbps are expected to see broader application in DCN networking, potentially extending their use to MAN and DCI platforms.

Related Blogs:
Exploration of Data Center Automated Operation and Maintenance Technology: Zero Configuration of Switches
Technology Feast | How to De-Stack Data Center Network Architecture
Technology Feast | A Brief Discussion on 100G Optical Modules in Data Centers
Research on the Application of Equal Cost Multi-Path (ECMP) Technology in Data Center Networks
Technology Feast | How to build a lossless network for RDMA
Technology Feast | Distributed VXLAN Implementation Solution Based on EVPN
Exploration of Data Center Automated Operation and Maintenance Technology: NETCONF
Technical Feast | A Brief Analysis of MMU Waterline Settings in RDMA Network
Technology Feast | Internet Data Center Network 25G Network Architecture Design
Technology Feast | The "Giant Sword" of Data Center Network Operation and Maintenance
Technology Feast: Routing Protocol Selection for Large Data Centre Networks
Technology Feast | BGP Routing Protocol Planning for Large Data Centres
Current assessments from major Internet companies indicate that within cluster environments, single-chip box switches are preferable to traditional chassis switches. In contrast, for the construction of metropolitan area networks (MAN) and data center interconnect (DCI) backbone infrastructures, a greater reliance on chassis switches is evident, particularly due to their large cache capacities and high port density on individual machines.
It is reasonable to anticipate that future enterprises will place increased demands on the performance, scalability, reliability, and cost of data center networks. As the capabilities of single-chip box switches continue to advance, systems with single-chip performance levels of 25.6 Tbps and 51.2 Tbps are expected to see broader application in DCN networking, potentially extending their use to MAN and DCI platforms.
Related Blogs:
Exploration of Data Center Automated Operation and Maintenance Technology: Zero Configuration of Switches
Technology Feast | How to De-Stack Data Center Network Architecture
Technology Feast | A Brief Discussion on 100G Optical Modules in Data Centers
Research on the Application of Equal Cost Multi-Path (ECMP) Technology in Data Center Networks
Technology Feast | How to build a lossless network for RDMA
Technology Feast | Distributed VXLAN Implementation Solution Based on EVPN
Exploration of Data Center Automated Operation and Maintenance Technology: NETCONF
Technical Feast | A Brief Analysis of MMU Waterline Settings in RDMA Network
Technology Feast | Internet Data Center Network 25G Network Architecture Design
Technology Feast | The "Giant Sword" of Data Center Network Operation and Maintenance
Technology Feast: Routing Protocol Selection for Large Data Centre Networks
Technology Feast | BGP Routing Protocol Planning for Large Data Centres
Featured blogs
- CXL 3.0: Solving New Memory Problems in Data Centres (Part 2)
- Ruijie RALB Technology: Revolutionizing Data Center Network Congestion with Advanced Load Balancing
- Multi-Tenant Isolation Technology in AIGC Networks—Data Security and Performance Stability
- Multi-dimensional Comparison and Analysis of AIGC Network Card Dual Uplink Technical Architecture
- A Brief Discussion on the Technical Advantages of the LPO Module in the AIGC Computing Power Network






